Parsing text - Finnish text - Any text
“Vierailin ystävän luona.” That is a sentence and it is Finnish. How do I parse that text? In order to get some meaning out of it?
The context of the question is text analytics. So that we could analyze the text, we need to extract some meaning of the words. For example, are there verbs in it and which words are verbs? What kind of sentences are in the text? Are there there a lot of words like “fail, fails, failed”? etc. etc
For machines/software, the sentence “Vierailin ystävän luona.” doesn’t really offer much. That’s why we want to parse it.
As it happens, there is something called Universal Dependencies. And part of Universal Dependencies is a format called CoNLL-U.
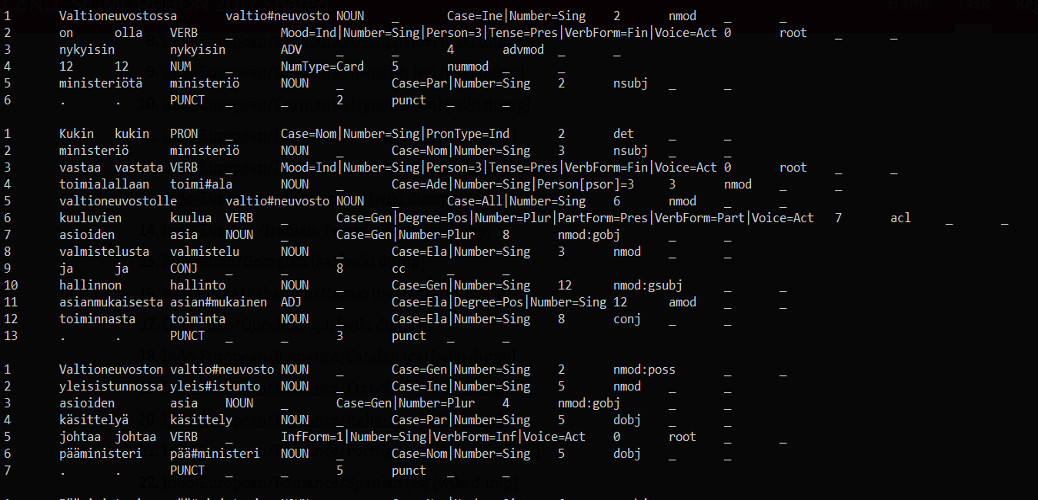
If we could get “Vierailin ystävän luona.” as CoNLL-U, we could get something out of it. For example: lemma, part of speech and a list of morphological features of the words.
So with CoNLL-U, our machines/software could get all the nouns very easily, we could get lemma of the word, we could get all the verbs, past or present tense and so on.
We are fortunate to have parser already available: Finnish dependency parser is built by the University of Turku NLP group. I wrapped the parser in Docker container and it is available for use at DockerHub. The source of the Docker container is also available.
Just pull the container and run it. Then send Finnish text “Vierailin ystävän luona.” as HTTP POST request to get the following CoNLL-U back:
1 Vierailin vierailla VERB _ Mood=Ind|Number=Sing|Person=1|Tense=Past|VerbForm=Fin|Voice=Act 0 root _ _
2 ystävän ystävä NOUN _ Case=Gen|Number=Sing 1 nmod _ _
3 luona luona ADP _ AdpType=Post 2 case _ _
4 . . PUNCT _ _ 1 punct _ _
CoNLL-U format includes tab-separated fields ID, FORM, LEMMA, UPOSTAG, XPOSTAG, FEATS, HEAD, DEPREL, DEPS and MISC.
There, much nicer for machines/software. We see immediately that “Vierailin” is a verb and it is past tense and single person. Lemma is “vierailla” and using translator, “vierailla” is “visit” in English. “Ystävän” is a noun and it is a “friend”. “luona” is adposition.
Text analytics can use CoNLL-U format and use that to do analytics. For example using lemma “vierailla” to find all sentences with that word would match all sentences that have “vierailen, vierailemme, vierailimme, vierailisimmeko” and so on. You could also search all sentences with past tense of “vierailla” and so on and so forth.
You could also do mining of the text like find something interesting from all the customer feedback you’ve received over the years. Or mine patient records to find anomalies or perhaps even detect an anomaly.
In practice, UIMA, the Unstructured Information Management Architecture, is commonly used when talking about text analytics. UIMA pipeline is a collection of annotators that do something about the text, for example a single annotator can find all names of the presidents or meeting rooms. Or single annotator can find email addresses. Or an annotator can get Finnish text and parse it to get CoNLL-U format out of it.
An excellent tool for content mining and text analytics is IBM Watson Explorer and it’s advanced content analytics capabilities 🙂